Amlsec – Automated Security Risk Identification Using AutomationML-based Engineering Data


This prototype identifies stability hazard resources (i.e., threats and vulnerabilities) and styles of assault repercussions based on AutomationML (AML) artifacts. The effects of the danger identification procedure can be used to generate cyber-bodily attack graphs, which product multistage cyber assaults that most likely direct to bodily injury.
Installation
- Build AML2OWL
This prototype depends on a forked version of the implementation of the bidirectional translation concerning AML and OWL for the ETFA 2019 paper “Interpreting OWL Complicated Classes in AutomationML dependent on Bidirectional Translation” by Hua and Hein. Clone the repository, compile the projects, and assemble an software bundle of aml_owl:
$ cd aml_designs
$ mvn cleanse compile install
$ cd ../aml_io
$ mvn clean up compile install
$ cd ../aml_owl
$ mvn cleanse compile install assembly:single
- Set up the AMLsec Foundation Listing
Clone this repository, build the software foundation directory (commonly located in the user’s household directory), and position the files found in amlsec-foundation-dir and the assembled AML2OWL JAR (situated in aml_owl/target/) there. The AMLsec foundation listing and the path to the AML2OWL JAR must be set in the configuration file making use of the keys baseDir and amlToOwlProgram, respectively.
- Set up Apache Jena Fuseki
Set up and begin Apache Jena Fuseki:
$ java -jar /fuseki-server.jar --update
- Build AMLsec
Eventually, establish and start the application by working with sbt.
$ sbt "runMain org.sba_investigate.employee.Key"
Utilization
The executed approach utilizes a semantic info mapping system recognized by implies of AML libraries. These AML stability extension libraries can be conveniently reused in engineering tasks by importing them into AML information.
The abilities of this prototype are demonstrated in a case analyze. Operating this prototype as is will yield the information foundation (can be accessed by using Fuseki), which also includes the success of the possibility identification procedure, and the pursuing pruned cyber-bodily assault graph:
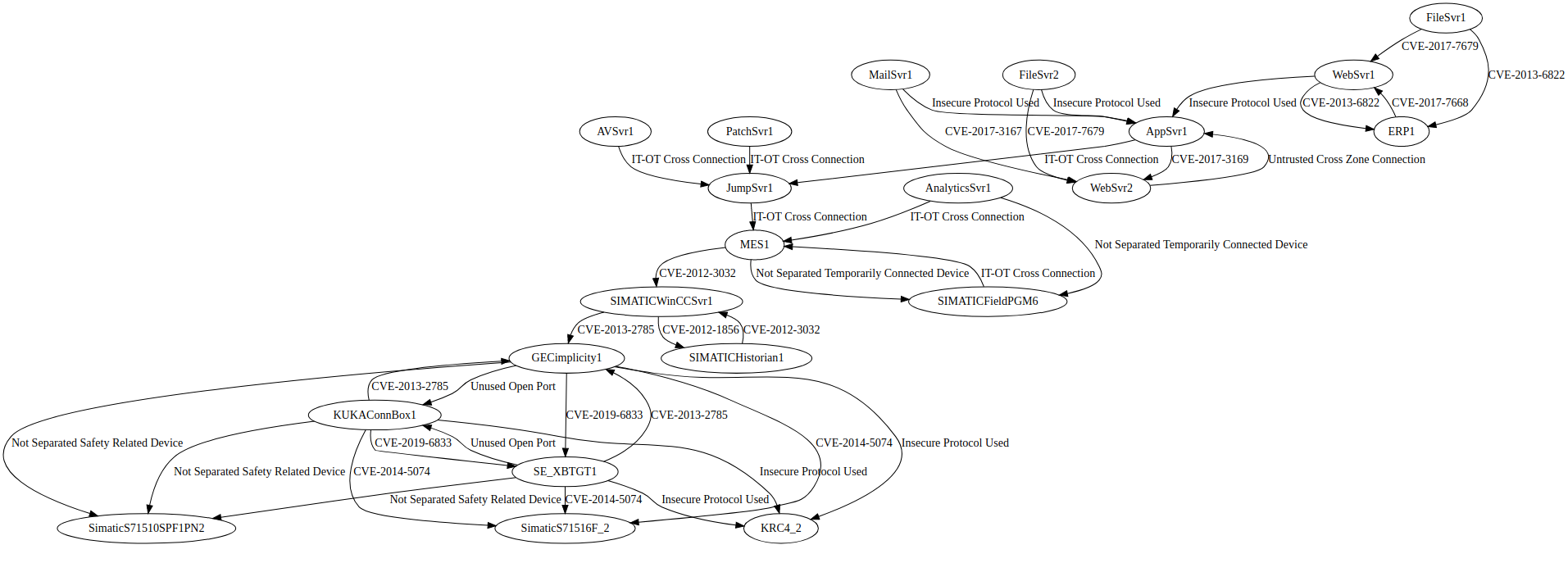
Cluster
The prototype makes use of the Akka framework and is ready to distribute the possibility identification workload among several nodes. The Akka dispersed personnel sample was applied as a template.
To run the cluster with several nodes:
- Begin Cassandra:
$ sbt "runMain org.sba_study.employee.Main cassandra"
- Start out the first seed node:
$ sbt "runMain org.sba_study.employee.Key 2551"
- Get started a front-finish node:
$ sbt "runMain org.sba_investigate.employee.Primary 3001"
- Begin a employee node (the next parameter denotes the range of worker actors, e.g., 3):
$ sbt "runMain org.sba_investigation.worker.Primary 5001 3"
If you run the nodes on independent equipment, you will have to adapt the Akka configurations in the configuration file.
Performance Evaluation
The measurements and log information acquired throughout the efficiency assessment are readily available on ask for.


